Gallery
Path of Titans mods
Mods in pages/paleo-presentation/mods/ — click a tile to open full size.








Mods in pages/paleo-presentation/mods/ — click a tile to open full size.
Screens from pages/paleo-presentation/game/ — click a tile to open full size.


1e-4 the best accuracy run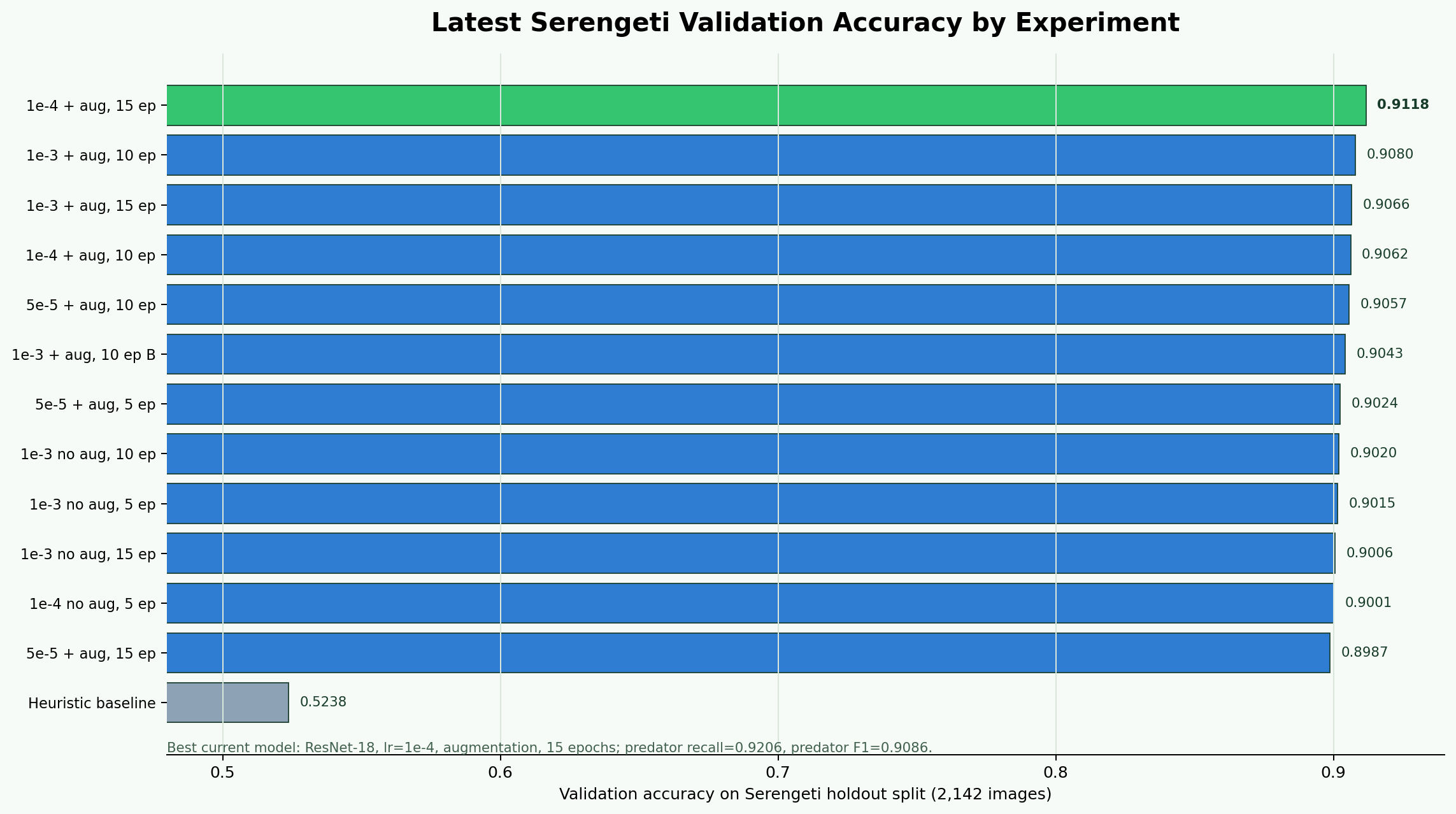
| Experiment | Val Accuracy | Pred Recall | Pred F1 | LR | Epochs |
|---|---|---|---|---|---|
| ResNet-18 LR=1e-4 + aug | 0.9118 | 0.9206 | 0.9086 | 1e-4 | 15 |
| ResNet-18 LR=1e-3 + aug | 0.9080 | 0.9020 | 0.9033 | 1e-3 | 10 |
| ResNet-18 LR=1e-3 + aug | 0.9066 | 0.9167 | 0.9034 | 1e-3 | 15 |
| ResNet-18 LR=1e-4 + aug | 0.9062 | 0.8990 | 0.9012 | 1e-4 | 10 |
| ResNet-18 LR=5e-5 + aug | 0.8987 | 0.8569 | 0.8896 | 5e-5 | 15 |
1e-4 + augmentation + 15 epochs was the strongest run, so we used it as the best real-image checkpoint before adapting to Path of Titans.
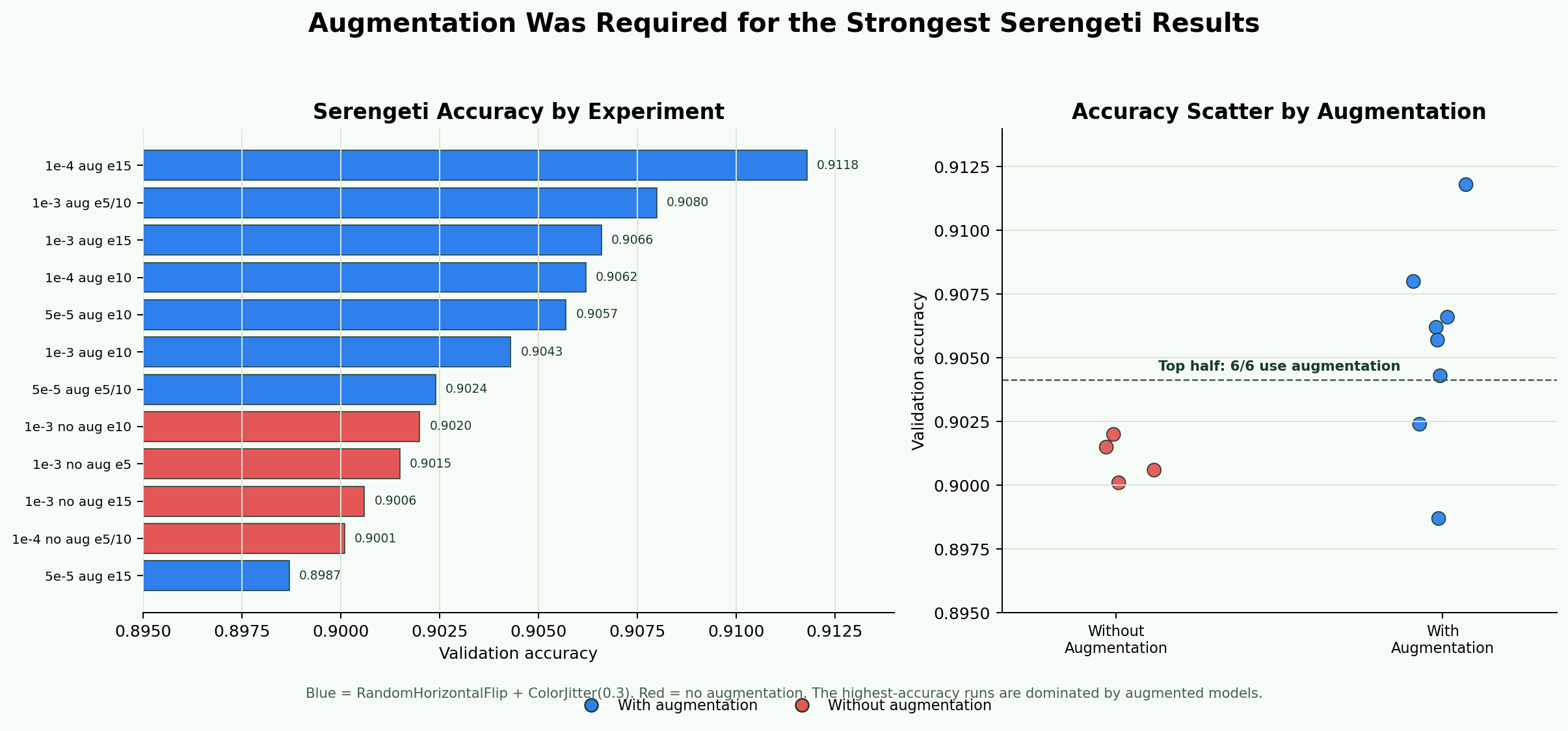
RandomHorizontalFlip and ColorJitter(0.3).0.9118 accuracy, 0.9206 predator recall, 0.9086 predator F1.
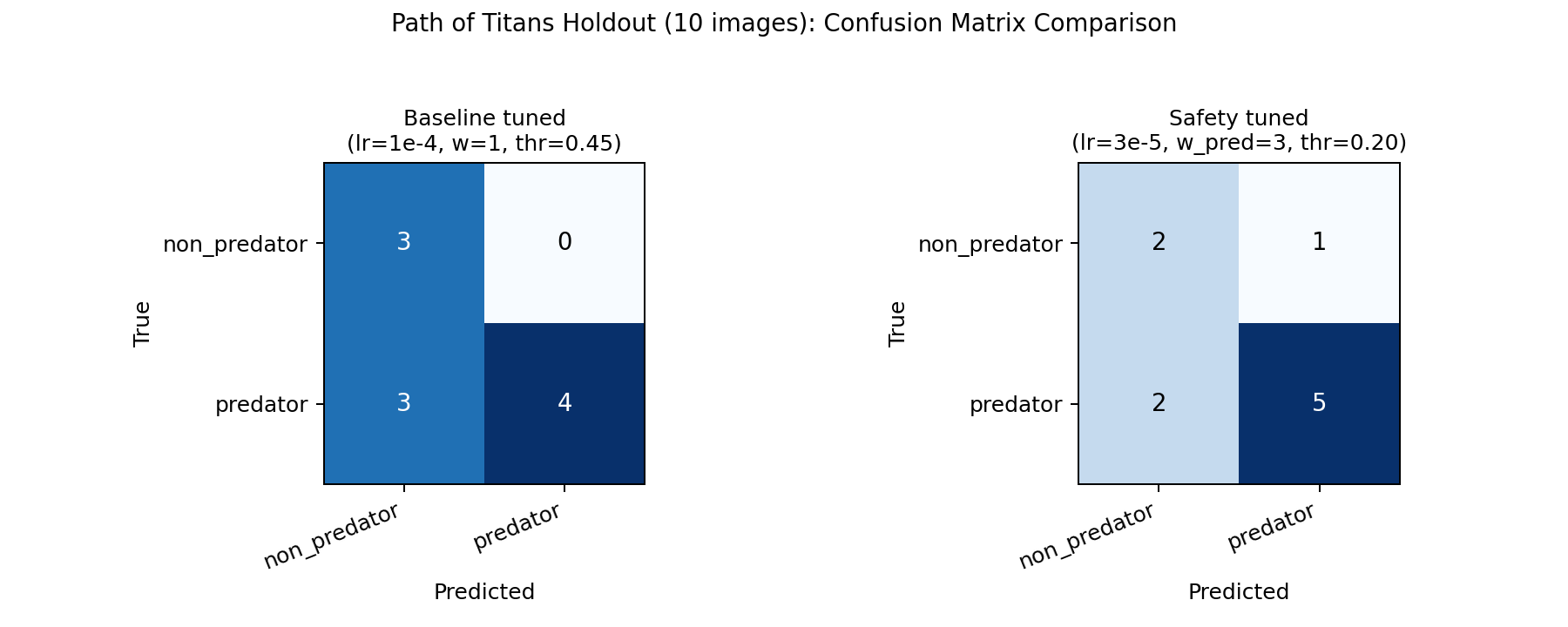
1e-4 is still the accuracy pick: it was strongest on Serengeti and on the 300-screenshot PoT validation split. But on the 10-image game holdout, class weighting alone did not fix false negatives at the default threshold. We switched from "best accuracy checkpoint" to a safety operating point: lr=3e-5, predator class weight 3.0, and threshold 0.20, because the live agent should over-warn rather than miss predators.
0.20 on the weighted run moved recall from 0.571 to 0.714 on the tiny holdout, trading one extra false alarm for fewer missed threats.